OK, you have been on expo, or are planning to go and the organisers have said that they don't need any more help (hah!). We always need help maintaining the records of cave explorations. We also always need help maintaining the software and documentation which helps us do this.
Possibly you are a programmer horrified by the apparently archaic software you have seen, possibly you just want to make sure that the work you did has been properly recorded and attributed, or maybe you have seen an obvious gap in the cross-referencing and would like to fix it.
We have a Expo Data To-Do List. If all you do is to check items on this list and email a nerd to tell them which have already been done then that would be excellent. And if you discover any bad or missing survey data then here is where you record the problem (see "Edit this page" below).
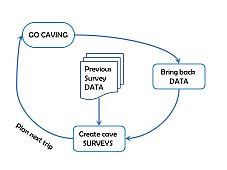
The biggest job after every expo is "tunneling": turning the typed-up survex data into drawings.

Cavers are usually pretty good, with some encouragement, at typing their survey notes into survex files and scanning their notes and underground sketches (in the plastic survey wallets) as scanfiles into the online wallets. But the outstanding tasks list after expo is always much longer than we would like. So the list of surveys attached to a cave is incomplete, as can be seen by looking at the scans of raw survey data or the the equivalent logbook records of trips for those dates.
There is always a backlog of surveyed caves that need their scanned centrelines annotating with the in-cave sketches, and then re-scanning and tracing using tunnel (or therion) to produce a survey. This is "tunneling".
We also have a simpler job of editing old survex files with the correct caver names such that old data is attributed. For example the trip to the deepest part of the SMKsystem is still not properly connected with the rest of the survey systems because the survex data uses an old format (this was Chaz Butcher, Andy Dolby and Pete Lancaster's trips to the Orgasm Chasm sump in 115 in 1982). In 1999 and earlier the scanned notes and wallets are not connected to the survex files either as you can see in the blank "survex blocks" column in the survey scans folders list.
The expo software system is a multi-decade long-term project. So it is probably unlike any software projects you have been involved with. It is quite unlike other Django projects.
The primary problem is lack of consistently available manpower. So modifications have to be compact and designed to be easily maintainable by time-constrained numpties in the future. So whatever you do has to be consistently documented (and in the manuals, not just in the code) otherwise it will just get thrown away by the next person.
There are few "clean" little programming jobs really. Nearly everything is intimately connected to the data formats of the expo and survey input data: survex files, tunnel files, therion files, logbook files, cave-description XML files, entrance files, survey-scans folders (wallets) and the workflow of turning scruffy notes into the finished survey documents we provide to the Austrians.
We have a Expo Systems To-Do List. If all you do is to test items on this list and delete those which have already been done then that would be excellent (use the "Edit this to-do list" big blue button on that page: and then email someone to tidy up the git checkin when you are done). And if you discover any bugs and - especially if you find a web page which crashes - then here is where you record the problem.
There are some simple jobs that don't require in-depth knowledge of large parts of the system, e.g. extracting diagrams from the scanned PDF copies of the logbooks and inserting them into the HTML version of the same logbook. There is a list of the logbooks that need doing in the "Logbook Fettling" section of the Expo Data To-Do List.
There are broken links in the handbook which need fixing. At the bottom of the survey laptop configuration page is a list of link-checking tools. Run one or more of these and use the "Edit this page" capability to fix the handbook pages so that the links work. This is a perennial problem with external websites which change their hosting systems and domain names too frequently for us to keep up with.
Before starting any coding you will need to have a good general feel for what the input data is and how it is handled. So please, please do a couple of data management jobs first - as described in the 'Survey Data' section above.
Many of the items on the Systems To-Do list won't make much sense until you have read through the expo systems architecture documents, and before you plan some changes have a look at the design decisions and proposals documents of the things we are already thinking about. And before you do anything, please do contribute a page or two on what you think would be a good idea (using the handbook editing "Edit this page" capability to add a new design document).
Your own laptop + web-browser is already a basic expo machine. You will need to install cave survey software to make it a then a survey laptop. This can take an hour or so, but you don't need to install everything before you can contribute to fixing things in the Expo Systems To-Do List. Once you have got a bit of experience with the how expo works, you can upgrade your laptop to a bulk update machine. If you really want to get stuck into the code you will need a troggle software development configuration.
Finally, if that all sounds like too much hassle for you, were are in desparate need of a lot more very simple tests for troggle. The more tests we have, the more confident we can be about making big changes without breaking things. We especially need these for the input parsers as whatever happens in the future, we are still going to need to parse the archived input files.
By contributing code and documentation to the expo systems you are assigning copyright under the OSI MIT open source license to CUCC (Cambridge University Caving Club). Note that Troggle is built with Django which uses the CC-BY-SA 3.0 creative commons license. Text and photographs, except where documenting code, are covered by a separate copyright process and by default this will be CC-BY-SA 3.0. Note that "Cambridge University" and other similar phrases are strictly controlled by the university.

