This is straightforward but a bit time-consuming. You need a Troggle software development machine and be happy running the python programe databaseReset.py at the command line. (The expo laptop is not a Troggle software development machine.)
Simply: we import all the logbook entries and blog posts for an expo into the database, then export them to a single file. This file is then used for future database resets.
This is the online UK Caving Blog for Expo 2022
It's a bit easy to get lost in this process and forget where you were, especially if you are interrupted. So it is handy to print out this page and tick off the steps as you do them.
After step 4, the blog posts appear in the list of logbook entries in the troggle Expo page for the year, correctly dated, and with titles such as "Expo - UK Caving Blog post 3".
The UK Caving Blog regularly upgrades its software which completely changes the hidden structure of the posts. They did this sometime between the 2017 and 2018 expos. When they do it again, the function parser_blog(year, expedition, txt, sq="") in troggle/parsers/logbooks.py will need to be completely re-written. It is currently 102 lines long and uses several regular expression recognizers.
If at all possible, we want to ensure that we preserve the GPS locations of the photos, if they are present as EXIF data in the .jpg files. But we also want to preserve the textual context. So, directly accessing the blog on the blog website, see if you can download a photograph directly and see if it has any EXIF/gps data in it. If so, contact a nerd who will help you extract and preserve it. (The code that adds uploaded images to Cave Description pages does this correctly, in troggle file editor_helpers.py .)
Now delete all the non-image files in the "ukcavingblog_files/" and "ukcavingblog2_files/" folders.
Now use your favourite photo editor (e.g. Irfanview on Windows) or a command-line tool to resize all the photos. A maximum of 800 pixels wide or high, or 400 or 300 pixels wide if the image quality is poor. Keep the same filename then you don't have to try to edit the horrendously horrible HTML which was generated by the blog software. If there are any .png files, convert them to .jpg.
There will be a lot. So install imagemagick and use the
mogrify tool:
mogrify -resize "900>x900>" *.jpg
will resize in-place, overwriting the files, and make the maximum dimension 900 pixels in either dimension, but preserving the aspect ratio (this is the "geometry" expression "900>x900>".
Look at all the photos in the file browser set to show thumbnails and delete all advertising logos etc., and delete the UK Caving header image which will be of random people not us.
Edit this bit in the obvious manner to add a line for the year you want to add:
BLOG_PARSER_SETTINGS = {
"2017": ("ukcavingblog.html", "parser_blog"),
"2018": ("ukcavingblog.html", "parser_blog"),
"2019": ("ukcavingblog.html", "parser_blog"),
"2022": ("ukcavingblog.html", "parser_blog"),
}
If there are 2nd or 3rd pageswithin the same year, these will be detected automatically. But you have to tell it about the first one.
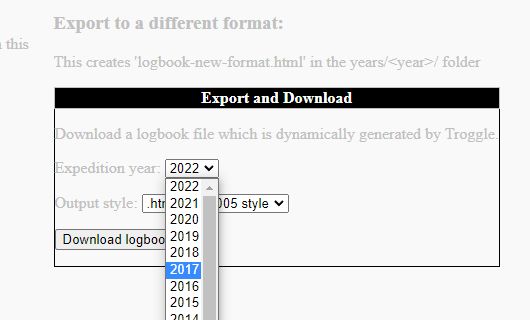
Run Troggle locally, and navigate your browser to http://localhost:8000/controlpanel. Select the drop-down for the year you are working on (2017 in this example).
You need to login as the "expoadmin" user id, not the usual "expo" id. This has a different password but you already know what it is because you set up your local copy of Troggle.
There is only one export format: "HTML 2005 style". This uses the Django template troggle/templates/logbook2005style.html.
All entries for the year will be exported in date order, which may not be the order they were originally written in the paper logbook.
Some logbooks have "front matter": text and images which are not part of any trip entry. This front matter is copied out when the logbook.html file was most recently parsed and is copied in to the front of the generated export file. The export file is always called "logbook-new-format.html" and is located in the same folder as "logbook.html". If there is a file of that name already there it is overwritten without warning.
Edit this bit in the obvious manner to show that you have done all the work for 2017. Don't just delete the line, make it obvious that the importing job was done:
BLOG_PARSER_SETTINGS = {
# "2017": ("ukcavingblog.html", "parser_blog"), # now folded in to logbooks.html
"2018": ("ukcavingblog.html", "parser_blog"),
"2019": ("ukcavingblog.html", "parser_blog"),
"2022": ("ukcavingblog.html", "parser_blog"),
}
In expoweb/years/current year/ :
At the command line, re-import the logbook using python databaseRest.py logbooks and look for errors in the terminal as it does it.
You have now consolidated the blog into the logbook, and put all the entries in date order too.
[ The true expert will edit parsers/imports.py to make the databaseReset option 'logbook' just do the year you are working on.]
With the blog, we have well known expoers labelled as unrecognized because while they posted to the blog, they were not actually on expo in that year. This is not a bug, but don't be confused by it.
Somewhere the encode/decode process of exporting the content of the trip writeups is turning quote marks into question marks, and > into >. Currently these are all being hand-edited to fix. The fault is somewhere in the settings for rendering a dictionary using a Django template, and hard to find and fix.
It it noticeable that a single blog post may cover several trips, and that the blog post date may be several days after the trip(s). So you need to manually find out the exact date of the trip (from the other trip records and particularly from the Bier Book) and change the date on the entry.
One blog post may also need to be split into several entries - don't worry about the 'id=' string as the parser now rewrites these uniquely. When you split a blog into different entries the quickest way to re-order everything in date-order is to export the logbook and re-import it.
The very last thing to do is to edit 'logbook.html' to remove the pre-expo training events and to put them into a file 'training-weekends.html', and to edit the 'index.html' file to link to that as well as to the logbook itself. This is necessary for the pre-expo material to get indexed by the server free-text indexer and search engine.
Back to Logbooks Import for Nerds documentation.
Back to Logbook internal format documentation.
Back to Logbooks for Cavers documentation.